ThoughtSpot caches data as relational tables in memory. The tables can be sourced from different data sources and joined together. ThoughtSpot has four ways to get data into the cluster:
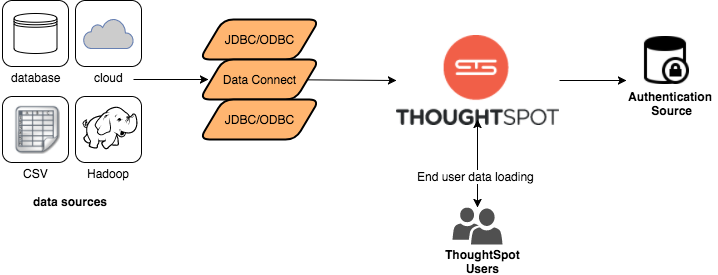
ThoughtSpot provides a JDBC and ODBC driver that can be used to write data to ThoughtSpot. This is useful for customers who already have an existing ETL process or tool and want to extend it to populate the ThoughtSpot cache.
Data Connect is a ThoughtSpot add-on that connects to a wide variety of data sources and pulls data into ThoughtSpot.
You can use the tsload command line tool to bulk load delimited data with very
high throughput. Finally, individual users can upload smaller (< 50MB)
spreadsheets or delimited files.
Which approach you use depends on your environment and data needs.
The following table shows the tradeoffs between different data caching options. Many implementations use a variety of approaches. For example, a solution with a large amount of initial data and smaller daily increments might use tsload to load the initial data and then use the JDBC driver with an ETL tool for incremental loads.
| JDBC/ODBC | Data Connect | tsload |
|---|---|---|
|
|
|